
Scraping data from a website is one the most underestimated technical and business moves I can think of. Scraping data online is something every business owner can do to create a copy of a competitor’s database and analyze the data to achieve maximum profit. It can also be used to analyze a specific market and find potential costumers. The best thing is that it is all free of charge. It only needs some technical skills which many people have these days. In this post I am going to do a step by step tutorial on how to scrape data from a website an saving it to a database. I will be using BeatifulSoup, a python library designed to facilitate screen scraping. I will also use MySQL as my database software. You can probably use the same code with some minor changes in order to use your desired database software.
Please note that scraping data from the internet can be a violation of the terms of service for some websites. Please do appropriate research before scraping data from the web and/or publishing the gathered data.
GitHup Page for This Project
I have also created a GitHub project for this blog post. I hope you will be able to use tutorial and code to customize it according to your need.
Python-Scraping-to-Database-Sample on GitHub
Requirements
- Basic knowledge of Python. (I will be using Python 3 but Python 2 would probably be sufficient too.)
- A machine with a database software installed. (I have MySQL installed on my machine)
- An active internet connection.
The following installation instructions are very basic. It is possible that the installation process for beautiful soup, Python etc. is a bit more complicated but since the installation is different on all different platforms and individual machines, it does not fit into the main object of this post, Scraping Data from a Website and saving it to a Database.
Installing Beautiful Soup
In order to install Beautiful Soup, you need to open terminal and execute one of the following commands according to your desired version of python. Please note that the following commands should probably be executed with “sudo” written before the actual line in order to give it administrative access.
For Python 2 (If pip did not work try it with pip2):
pip install beautifulsoup4
For Python 3:
pip3 install beautifulsoup4
If the above did not work, you can also use the following command.
For Python 2:
apt-get install python-bs4
For Python 3:
apt-get install python3-bs4
If you were not able to install beautiful soup, just Google the term “How to install Beautiful Soup” and you will find plenty of tutorials.
Installing MySQLdb
In order to able to connect to your MySQL databases through Python, you will have to install MySQLdb library for your Python installation. Since Python 3 does not support MySQLdb at the time of this writing, you will need to use a different library. It is called mysqlclient which is basically a fork of MySQLdb with an added support for Python 3 and some other improvements. So using the library is basically identical to native MySQLdb for Python 2.
To install MySQLdb on Python 2, open terminal and execute the following command:
pip install MySQL-python
To install mysqlclient on Python 3, open terminal and execute the following command:
pip3 install mysqlclient
Installing requests
requests is a Python library which is used to load html data from a url. In order to install requests on your machine, follow the following instructions.
To install requests on Python 2, open terminal and execute the following command:
pip install requests
To install requests on Python 3, open terminal and execute the following command:
pip3 install requests
Now that we have everything installed and running, let’s get started.
Step by Step Guide on Scraping Data from a Single Web Page
I have created a page with some sample data which we will be scraping data from. Feel free to use this url and test your code. The page we will be scraping in the course of this article is https://howpcrules.com/sample-page-for-web-scraping/.
1. First of all we have to create a file called “scraping_single_web_page.py”.
2. Now, we will start by importing the libraries requests, MySQLdb and BeautifulSoup:
import requests import MySQLdb from bs4 import BeautifulSoup
3. Let us create some variables where we will be saving our database connection data. To do so, add the below lines in your “” file.
#SQL connection data to connect and save the data in HOST = "localhost" USERNAME = "scraping_user" PASSWORD = "" DATABASE = "scraping_sample"
4. We also need a variable where we will save the url to be scraped, into. After that, we will use the imported library “requests” to load the web page’s html plain text into the variable “plain_html_text”. In the next line, we will use BeautifulSoup to create a multidimensional array, “soup” which will be a big help to us in reading out the web page’s content efficiently.
#URL to be scraped url_to_scrape = 'https://howpcrules.com/sample-page-for-web-scraping/' #Load html's plain data into a variable plain_html_text = requests.get(url_to_scrape) #parse the data soup = BeautifulSoup(plain_html_text.text, "html.parser")
Your whole code should be looking like this till now:
import requests import MySQLdb from bs4 import BeautifulSoup #SQL connection data to connect and save the data in HOST = "localhost" USERNAME = "scraping_user" PASSWORD = "" DATABASE = "scraping_sample" #URL to be scraped url_to_scrape = 'https://howpcrules.com/sample-page-for-web-scraping/' #Load html's plain data into a variable plain_html_text = requests.get(url_to_scrape) #parse the data soup = BeautifulSoup(plain_html_text.text, "html.parser")
These few lines of code were enough to load the data from the web and parse it. Now we will start the task of finding the specific elements we are searching for. To do so we have to take a look at the page’s html and find the elements we are looking to save. All major web browsers offer the option to see the html plain text. If you were not able to see the html plain text on your browser, you can also add the following code the end of your “scraping_single_web_page.py” file to see the loaded html data in your terminal window.
print(soup.prettify())
To execute the code open terminal, navigate to the folder where you have your “scraping_single_web_page.py” file and execute your code with “python scraping_single_web_page.py” for Python 2 or “python3 scraping_single_web_page.py” respectively. Now, you will see the html data printing out in your terminal window.
5. Scroll down until you find my html comment “<!– Start Sample Data to be Scraped –>”. This is were the actual data we need starts. As you can see, the name of the class “Exercise: Data Structures and Algorithms” is written inside a <h3> tag. Since this is the only h3 tag in the whole page, we can use “soup.h3” to get this specific tag and its contents. We will now use the following command to get the whole tag where the name of the class is written in and save the content of the tag into the variable “name_of_class”. We will also use Python’s strip() function to remove all possible spaces to the left and right of the text. (Please note that the line print(soup.prettify()) was only there to print out the html data and can be deleted now.)
#Get the name of the class name_of_class = soup.h3.text.strip()
6. If you scroll down a little bit, you will see that the table with the basic information about the class is identified with summary=”Basic data for the event” inside its <table> tag. So we will save the parsed table in a variable called “basic_data_table”. If you take a closer look at the tags inside the table you will realize that the data itself regardless of its titles are saved inside <td> tags. These <td> tags have the following order from top to down:
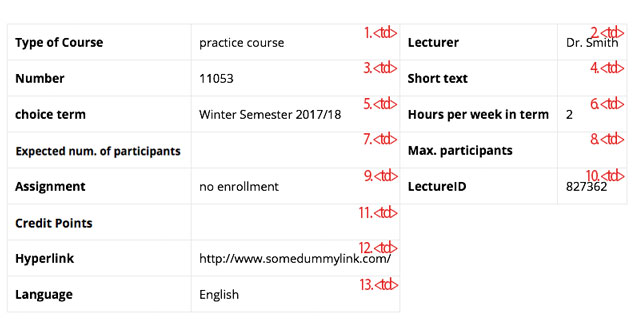
According to the above, all text inside the <td> tags are relevant and need to be stored in appropriate variables. To do so we first have to parse all <td>s inside our table.
#Get all data associated with this class
basic_data_table = soup.find("table", {"summary": "Basic data for the event"});
#Get all cells in the base data table
basic_data_cells = basic_data_table.findAll('td')
7. Now that we have all <td>s stored in the variable “basic_data_cells”, we have to go through the variable and save the data accordingly. (Please note that the index in arrays start from zero. So the numbers in the above picture will be shifted by one.)
#get all the different data from the table's tds type_of_course = basic_data_cells[0].text.strip() lecturer = basic_data_cells[1].text.strip() number = basic_data_cells[2].text.strip() short_text = basic_data_cells[3].text.strip() choice_term = basic_data_cells[4].text.strip() hours_per_week_in_term = basic_data_cells[5].text.strip() expected_num_of_participants = basic_data_cells[6].text.strip() maximum_participants = basic_data_cells[7].text.strip() assignment = basic_data_cells[8].text.strip() lecture_id = basic_data_cells[9].text.strip() credit_points = basic_data_cells[10].text.strip() hyperlink = basic_data_cells[11].text.strip() language = basic_data_cells[12].text.strip()
8. Let’s continue with the course dates. Like the previous table, we have to parse the tables where the dates are written. The only difference is that for the dates, there is not only one table to be scraped but several ones. To do so we will use the following to scrape all tables into one variable:
#Get the tables where the dates are written.
dates_tables = soup.find_all("table", {"summary": "Overview of all event dates"});
9. We now have to go through all the tables and save the data accordingly. This means we have to create a for loop to iterate through the tables. In the tables, there is always one row (<tr> tag) as the header with <th> cells inside (No <td>s). After the header there can one to several rows with data that do interest us. So inside our for loop for the tables, we also have to iterate through the individual rows (<tr>s) where there is at least one cell (<td>) inside in order to exclude the header row. Then we only have to save the contents inside each cell into appropriate variables.

This all is translated into code as follows:
#Iterate through the tables
for table in dates_tables:
#Iterate through the rows inside the table
for row in table.select("tr"):
#Get all cells inside the row
cells = row.findAll("td")
#check if there is at least one td cell inside this row
if(len(cells) > 0):
#get all the different data from the table's tds
#Split this cell into two different parts seperated by 'to' in order to have a start_date and an end_date.
duration = cells[0].text.split("to")
start_date = duration[0].strip()
end_date = duration[1].strip()
day = cells[1].text.strip()
#Split this cell into two different parts seperated by 'to' in order to have a start_time and an end_time.
time = cells[2].text.split("to")
start_time = time[0].strip()
end_time = time[1].strip()
frequency = cells[3].text.strip()
room = cells[4].text.strip()
lecturer_for_date = cells[5].text.strip()
status = cells[6].text.strip()
remarks = cells[7].text.strip()
cancelled_on = cells[8].text.strip()
max_participants = cells[9].text.strip()
Please note that the above code reads the data and overrides them in the same variables over and over again so we have to create a database connection and save the data in each iteration.
Saving Scraped Data into a Database
Now, we are all set to create our tables and save the scraped data. To do so please follow the steps below.
10. Open your MySQL software (PhpMyAdmin, Sequel Pro etc.) on your machine and create a database with the name “scraping_sample”. You also have to create a user with name “scraping_sample_user”. Do not forget to at least give write privileges to the database “scraping_sample” for the user “scraping_user”.
11. After you have created the database navigate to the “scraping_sample” database and execute the following command in your MySQL command line.
CREATE TABLE `classes` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name_of_class` varchar(255) COLLATE utf8_unicode_ci NOT NULL, `type_of_course` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `lecturer` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `number` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `short_text` text COLLATE utf8_unicode_ci DEFAULT NULL, `choice_term` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `hours_per_week_in_term` varchar(255) COLLATE utf8_unicode_ci NOT NULL, `expected_num_of_participants` varchar(255) COLLATE utf8_unicode_ci NOT NULL, `maximum_participants` varchar(255) COLLATE utf8_unicode_ci NOT NULL, `assignment` varchar(255) COLLATE utf8_unicode_ci NOT NULL, `lecture_id` varchar(255) COLLATE utf8_unicode_ci NOT NULL, `credit_points` varchar(255) COLLATE utf8_unicode_ci NOT NULL, `hyperlink` text COLLATE utf8_unicode_ci DEFAULT NULL, `language` varchar(255) COLLATE utf8_unicode_ci NOT NULL, `created_at` timestamp NULL DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci; CREATE TABLE `events` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `class_id` int(10) unsigned NOT NULL, `start_date` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `end_date` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `day` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `start_time` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `end_time` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `frequency` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `room` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `lecturer_for_date` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `status` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `remarks` text COLLATE utf8_unicode_ci, `cancelled_on` text COLLATE utf8_unicode_ci, `max_participants` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `created_at` timestamp NULL DEFAULT NULL, PRIMARY KEY (`id`), KEY `events_class_id_foreign` (`class_id`), CONSTRAINT `events_class_id_cascade` FOREIGN KEY (`class_id`) REFERENCES `classes` (`id`) ON DELETE CASCADE ) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
Now you have two tables with the classes in the first one and the corresponding events in the second one. We have also created a foreign key from the events table to the classes table. We also added a constraint to delete the events associated with a class if the class is removed (on delete cascade).
We can go back to our code “scraping_single_web_page.py” and start with the process of saving data to the database.
12. In your code, navigate to the end of step 7, the line “language = basic_data_cells[12].text.strip()” and add the following below that to be able to save the class data:
#Save class's base data to the database
# Open database connection
db = MySQLdb.connect(HOST, USERNAME, PASSWORD, DATABASE)
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Prepare SQL query to INSERT a record into the database.
sql = "INSERT INTO classes(name_of_class, type_of_course, lecturer, number, short_text, choice_term, hours_per_week_in_term, expected_num_of_participants, maximum_participants, assignment, lecture_id, credit_points, hyperlink, language, created_at) VALUES ('{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}', {})".format(name_of_class, type_of_course, lecturer, number, short_text, choice_term, hours_per_week_in_term, expected_num_of_participants, maximum_participants, assignment, lecture_id, credit_points, hyperlink, language, 'NOW()')
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
#get the just inserted class id
sql = "SELECT LAST_INSERT_ID()"
try:
# Execute the SQL command
cursor.execute(sql)
# Get the result
result = cursor.fetchone()
# Set the class id to the just inserted class
class_id = result[0]
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()
# on error set the class_id to -1
class_id = -1
Here, we use the MySQLdb library to establish a connection to the MySQL server and insert the data into the table “classes”. After that, we execute a query to get back the id of the just inserted class the value is saved in the “class_id” variable. We will use this id to add its corresponding events into the events table.
13. We will now save each and every event into the database. To do so, navigate to the end of step 9, the line “max_participants = cells[9].text.strip()” and add the following below it. Please note that the following have to be exactly below that line and inside the last if statement.
#Save event data to database
# Open database connection
db = MySQLdb.connect(HOST, USERNAME, PASSWORD, DATABASE)
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Prepare SQL query to INSERT a record into the database.
sql = "INSERT INTO events(class_id, start_date, end_date, day, start_time, end_time, frequency, room, lecturer_for_date, status, remarks, cancelled_on, max_participants, created_at) VALUES ('{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}', {})".format(class_id, start_date, end_date, day, start_time, end_time, frequency, room, lecturer_for_date, status, remarks, cancelled_on, max_participants, 'NOW()')
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()
here, we are using the variable “class_id” first mentioned in step 12 to add the events to the just added class.
Scraping Data from Multiple Similar Web Pages
This is the easiest part of all. The code will work just fine if you have different but similar web pages you would like to scrape data from. Just put the whole code excluding the steps 1-3 in a for loop where the “url_to_scrape” variable is dynamically generated. I have created a sample script where the same page is scraped a few times over to elaborate this process. To check out the script and the fully working example of the above, navigate to my “Python-Scraping-to-Database-Sample” GitHub page.


